The WID is a database structure to facilitate communication and data sharing between states. It takes common data products and puts them in a format that 1) saves states the work of coming up with their own and creating the documentation to support and maintain it and 2) allows them to use common terms or formats in communications with other states. For these reasons, maintaining data in the prescribed WID format is funded by an ETA grant. However, there can sometimes be confusion about what parts of the WID are required deliverables.
The WID structure document is 146 pages long and includes structure and value information for more than 200 tables, not all of which have available data in every state or jurisdiction.
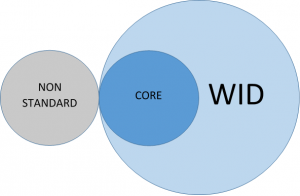
Required “core” tables – these are largely those tables for which state LMI offices already have BLS data and are summarized in Appendix C. Only core tables are mandated by the ETA grant.
Non-core tables are included for several possible reasons:
- They’re likely to be needed by states, or are used by a significant percentage of states. This includes lookup tables of occupation and industry codes, crosswalks between different coding systems.
- The data is readily available and provided in WID format by the ARC – population, demographics, and income, for example. These are subjects that are of interest to many state LMI offices and having them in a consistent format has the potential to reduce state workload.
- They’re emerging as an area of interest or are core products of a few states. This might include the programs table (which houses IPEDS data, emerging as an area of interest because of WIOA requirements) or the JVS table, which houses job vacancy data some states collect.
Non-standard tables: ARC documentation and files exists for tables that aren’t in the formal WID structure document but are structured such that they could work seamlessly with it, using the same geographic and time references and relating back to the same lookup tables. These include geogxzip and some tax and GDP files. Some WID non-core tables started as non-standard tables, were found to be useful, and made it into the structure document later on.